How Do Servers Handle Multiple Requests Simultaneously (Python, WSGI, Gunicorn)?
Servers can handle requests in different ways, utilizing threads or processes. Some examples include:
- Servers that use a single thread to serve all requests
- Servers that assign a thread for each request
- Servers that run in a single process
- Servers that run in multiple processes
- Multiple instances of the server can be deployed simultaneously
Good thing to remember about threads is that creating, assigning and switching threads is slow → In some cases using fewer threads can result in better performance.
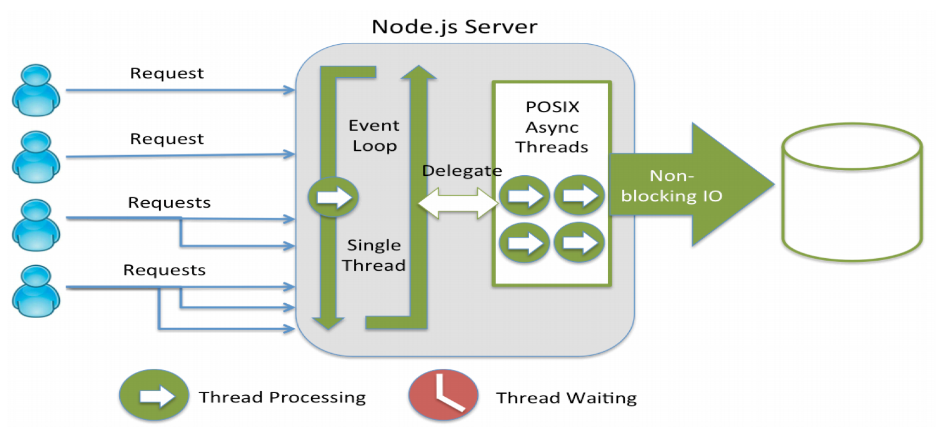
Node.js server handling requests with a single thread
E.g. Java server handling requests with multiple threads (thread pool)
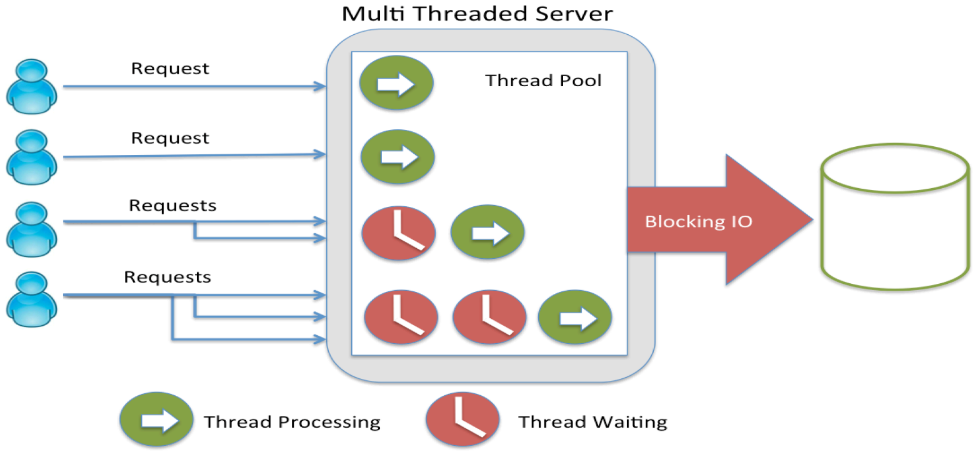
Images from: https://www.luxoft-training.com/news/reactive-programming-in-java-how-why-and-is-it-worth-doing-node-js/
Internally Node.js server also uses thread pool. In Node, I/O operations are offloaded to the C++ APIs (libuv) which allows the Node.js main-thread to continue executing your code without having to wait for file or network operations to finish.
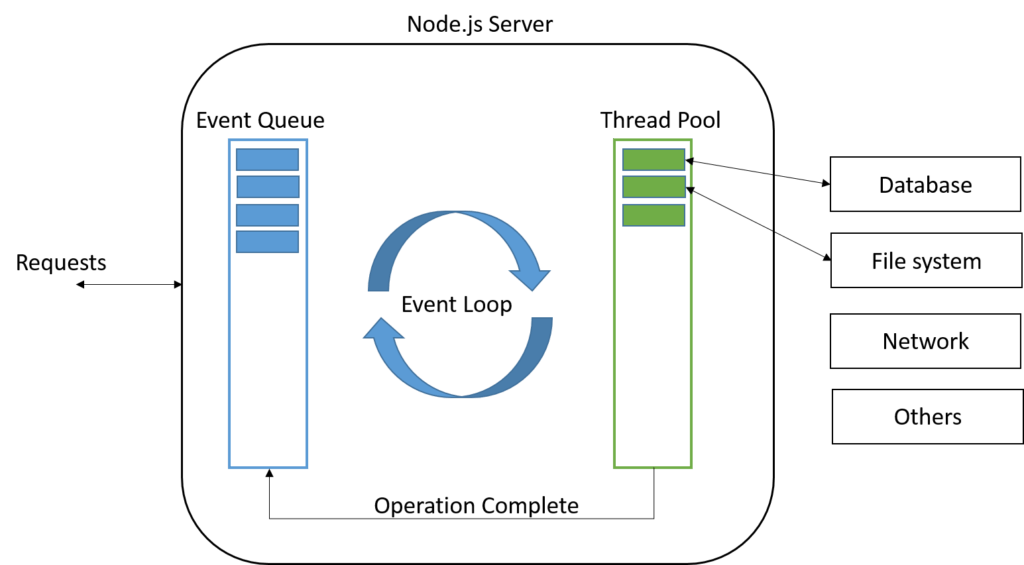
https://www.pabbly.com/tutorials/node-js-event-loops/
The secret to the scalability of Node.js is that it uses a small number of threads to handle many clients. If Node.js can make do with fewer threads, then it can spend more of your system’s time and memory working on clients rather than on paying space and time overheads for threads (memory, context-switching). But because Node.js has only a few threads, you must structure your application to use them wisely.
https://nodejs.org/en/docs/guides/dont-block-the-event-loop/
What Is Fast? -> Benchmarks
https://www.techempower.com/benchmarks/
What actually qualifies as ‘fast’ in real-life scenarios? More importantly, how can we determine what is sufficient for our specific use case?
Things to consider:
- How many simultaneous users our service has?
- How many requests users create per second?
- How many of these requests are unique?
- How many requests can be served from cache?
- …?
Basic web application requires quite a lot of simultaneous users that raw performance start to really matter. Especially if proper caching is used. If each customer request is e.g. customer specific, then common caching is not an option and performance is even more important.
Do Servers Handle Requests Concurrently or in Parallel?
Concurrency relates to an application that is processing more than one task at the same time.
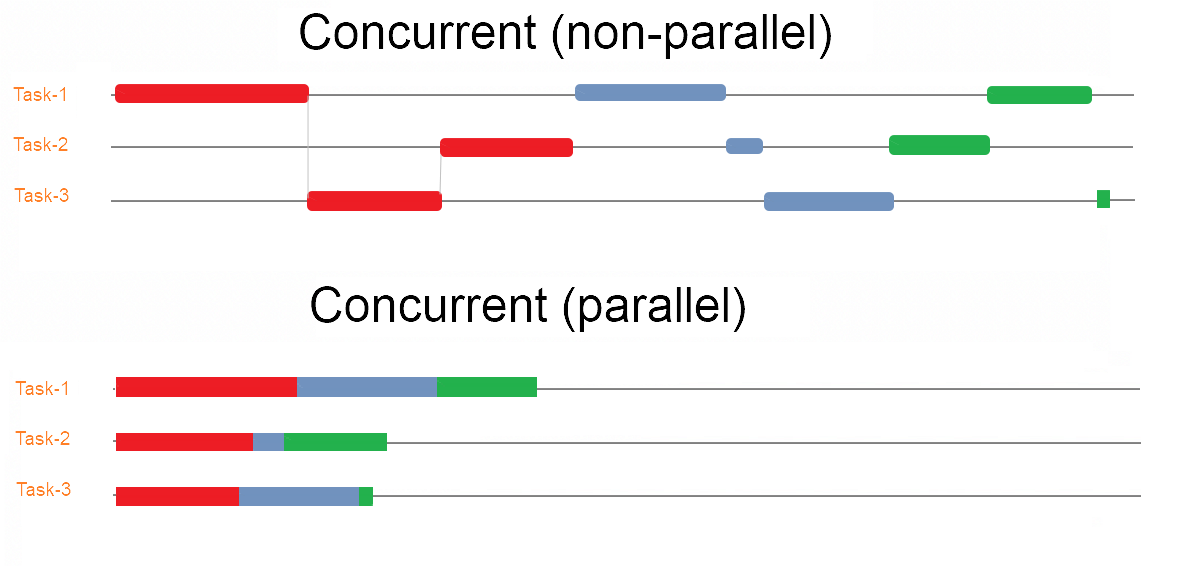 Image from: https://commons.wikimedia.org/wiki/File:Parallel-concurrent.png
Image from: https://commons.wikimedia.org/wiki/File:Parallel-concurrent.png
{kind=link}
How Threads Work in Python
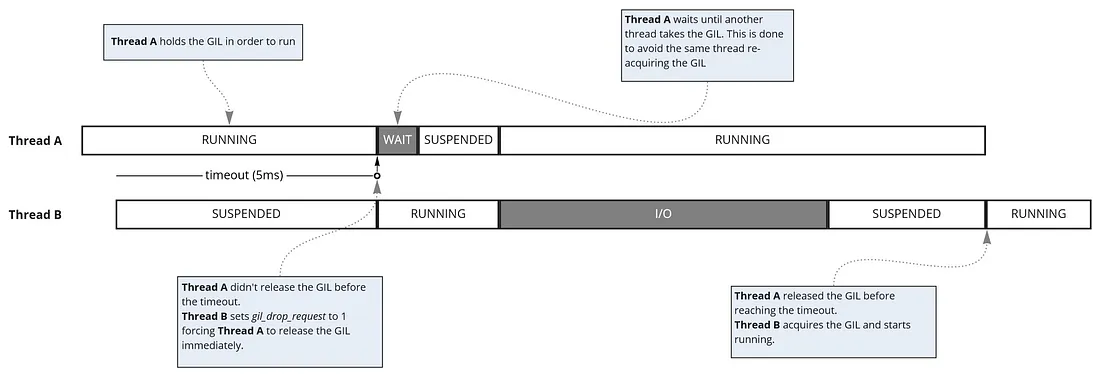
Image from: https://luis-sena.medium.com/gunicorn-vs-python-gil-221e673d692
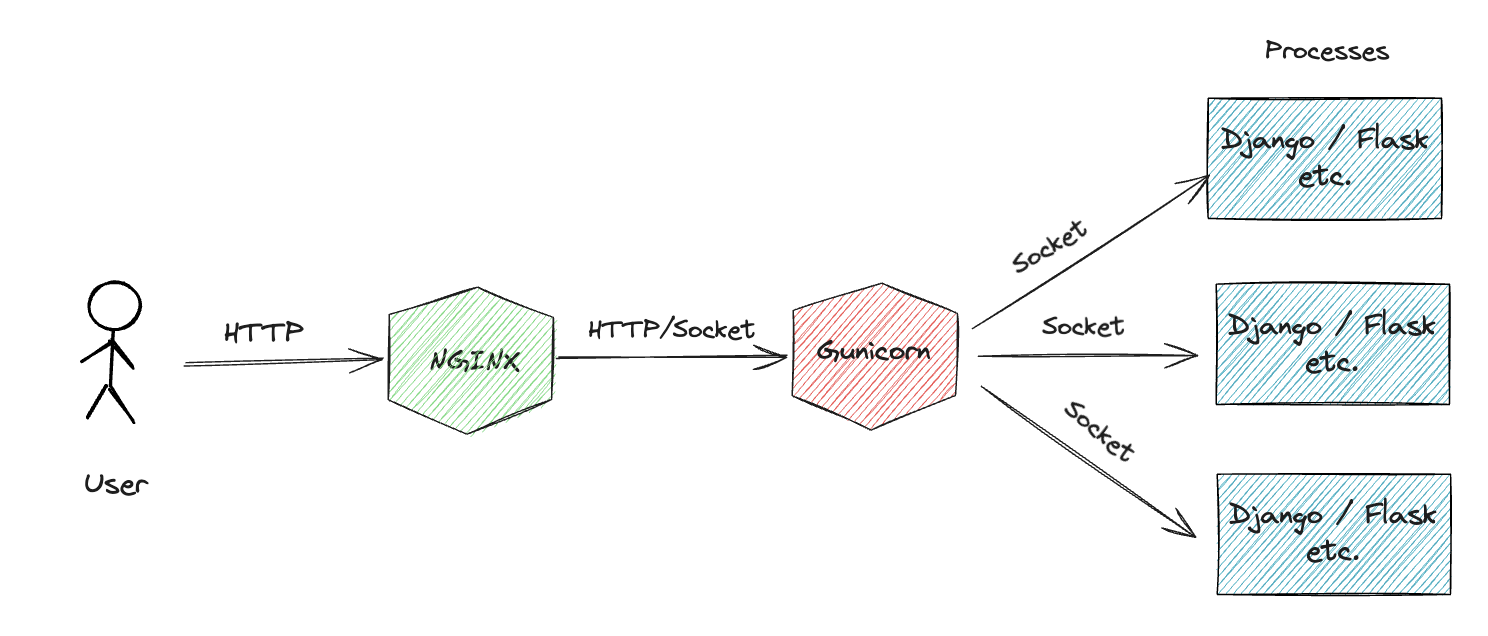
Gunincorn (WSGI)
WSGI is Web Socket Gateway Interface. its purpose is to relay HTTP requests from the webserver to the Django application, as well as to relay responses from the application back to the webserver. WSGI is described by the PEP 3333 standard, and partially serves to decouple your Python application from a webserver, making it more platform-agnostic
Workers:
Worker is a new process. Each worker can run parallel.
Threads:
Thread is a execution process inside a process. With threads the process can execute multiple things at the same time (in some languages). Why threads? More lightweight, share memory space, can easily distribute execution to multiple threads and combine result.
In Python only single thread can execute at a time (GIL). When one thread is doing an I/O operation (e.g. DB or API request) other thread can continue execution.
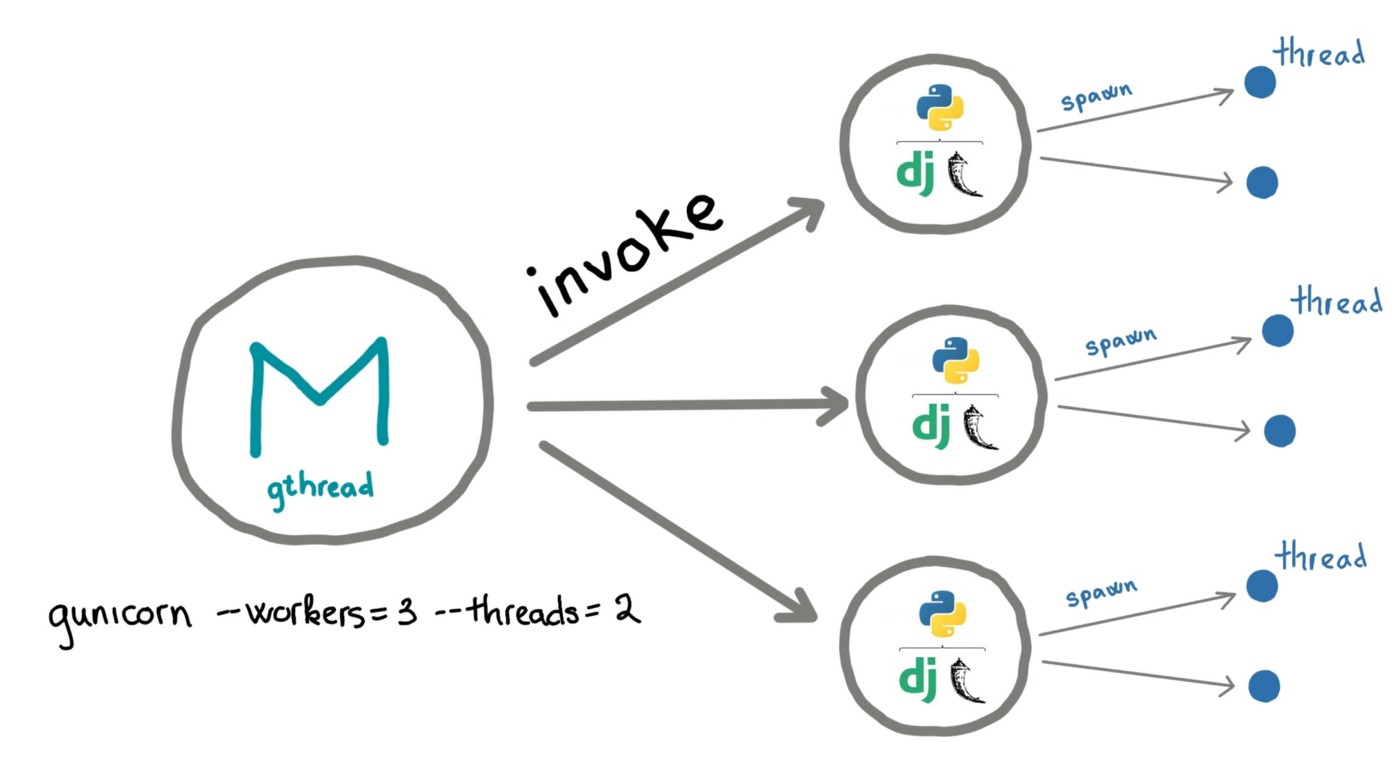 Image from: https://medium.com/@nhudinhtuan/gunicorn-worker-types-practice-advice-for-better-performance-7a299bb8f929
Image from: https://medium.com/@nhudinhtuan/gunicorn-worker-types-practice-advice-for-better-performance-7a299bb8f929
Besides threads, Python has couroutines and greenlets.
Thread vs Coroutine (Async)
- Thread is object, coroutine is function
- Switching and suspending functions is faster than switching and suspending objects
- Still locked, no real parallelism
Thread vs Greenlets
- Greenlets are like application controlled threads
- Coroutine is same as greenlet
Read more from: https://medium.com/@nhudinhtuan/gunicorn-worker-types-practice-advice-for-better-performance-7a299bb8f929