Efficiently Securing Web Applications Against High User Peaks and Denial-of-Service Attacks
Security is a large topic. This post is aimed at developers and focuses on the security of customer-facing APIs. This post gives tips on how to make sure the system can handle large user peaks and how to prevent malicious users from crashing the system by sending multiple requests (denial-of-service attack). Executing this kind of attack is easy and can be done by almost anyone.
Every web application that exposes APIs to the public is at risk of denial-of-service attacks. These attacks can overwhelm your servers, causing them to crash or become unresponsive. This can lead to data loss, service downtime, and reputational damage.
High user peaks can occur with almost any service, often triggered by a marketing campaign, a viral post, or a sudden surge in demand for your service. If the application is not adequately prepared, these peaks can result in consequences similar to those of a denial-of-service attack.

With these simple yet effective methods, you can enhance the security of your APIs while improving performance, ensuring the application can handle any number of users. This setup also lays a solid foundation for scaling the application to meet growing user demand.
These measures can be implemented rather easily on top of your existing API infrastructure, regardless of the technology stack, service provider or size of your application.
Some of these measures can be implemented in the application code and some can be implemented in the different parts of the infrastructure.

Different providers offer various services that can be used to implement the infrastructure, and these services can be mixed and matched based on availability and requirements.
| Solution | WAF | CDN | Storage | Load Balancer | Compute | Database |
|---|---|---|---|---|---|---|
| AWS | AWS WAF | CloudFront | S3 | API Gateway / ELB | Elastic Beanstalk | RDS |
| Azure | Azure WAF | Azure CDN | Azure Blob Storage | Azure API Management | Azure App Service | Azure SQL |
| Mixed | CloudFlare WAF | CloudFlare | Heroku Static Assets | Heroku API Routing | Heroku | Aiven |
| Kubernetes | Akamai WAF | Akamai | MinIO / Static files | Ingress | Nodes & Pods | Postgres |
Refer to the example project for instructions on how to run the infrastructure locally using Docker: Example project
Checklist
This post covers some key areas you should focus on to improve the security posture of your application while ensuring its performance and scalability. This checklist is not a complete list, but it provides a solid foundation for securing your APIs.
- Do Not Leave Open Endpoints
- Cache As Much As Possible
- Rate Limiting
- Blocking A User
- Duplicate Identical Request Detection and Prevention
- Idempotency
- Web Application Firewall
- Documented Plan for When the System is Under Attack
Do Not Leave Open Endpoints
As customer-facing APIs can’t be hidden from the public, it is important to ensure that only authorized users can access them. Open endpoints should be avoided unless absolutely necessary.
Ensure that all endpoints in your APIs have proper authorization mechanisms in place. This can help prevent unauthorized access to sensitive data and prevent unnecessary load on the system.
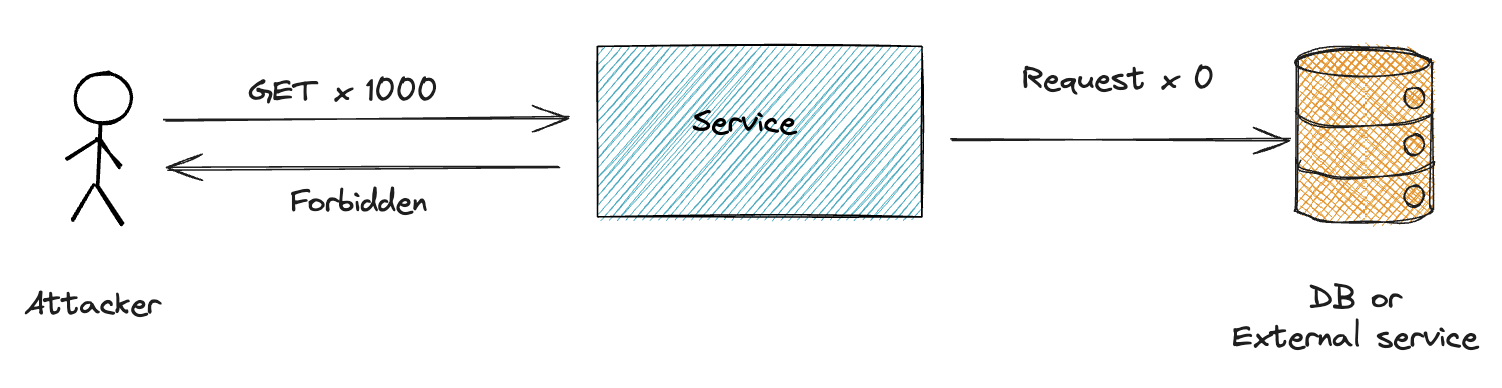
Remember that authenticated users can still be threats. If a customer is allowed to have unlimited access after the authentication, it will leave a door open for attackers to try to crash the system by creating multiple accounts and sending multiple requests.
Cache as Much as Possible
Implement caching to protect your APIs from denial-of-service attacks. It also reduces the load on your servers and improves response times for users. Multiple benefits in one!
Cache can be implemented in various ways, but good practice is to implement it as close to customer as possible. This means less load on the servers and faster response times for the users.
Common factors to consider when deciding where to cache data include:
- Access to Infrastructure: Where can you implement caching? Do you have access to the CDN, Load Balancer, or application code?
- Fine-grained Control: How much control do you need over the cache? Do you need to cache based on HTTP headers, cookies, or other application-level data?
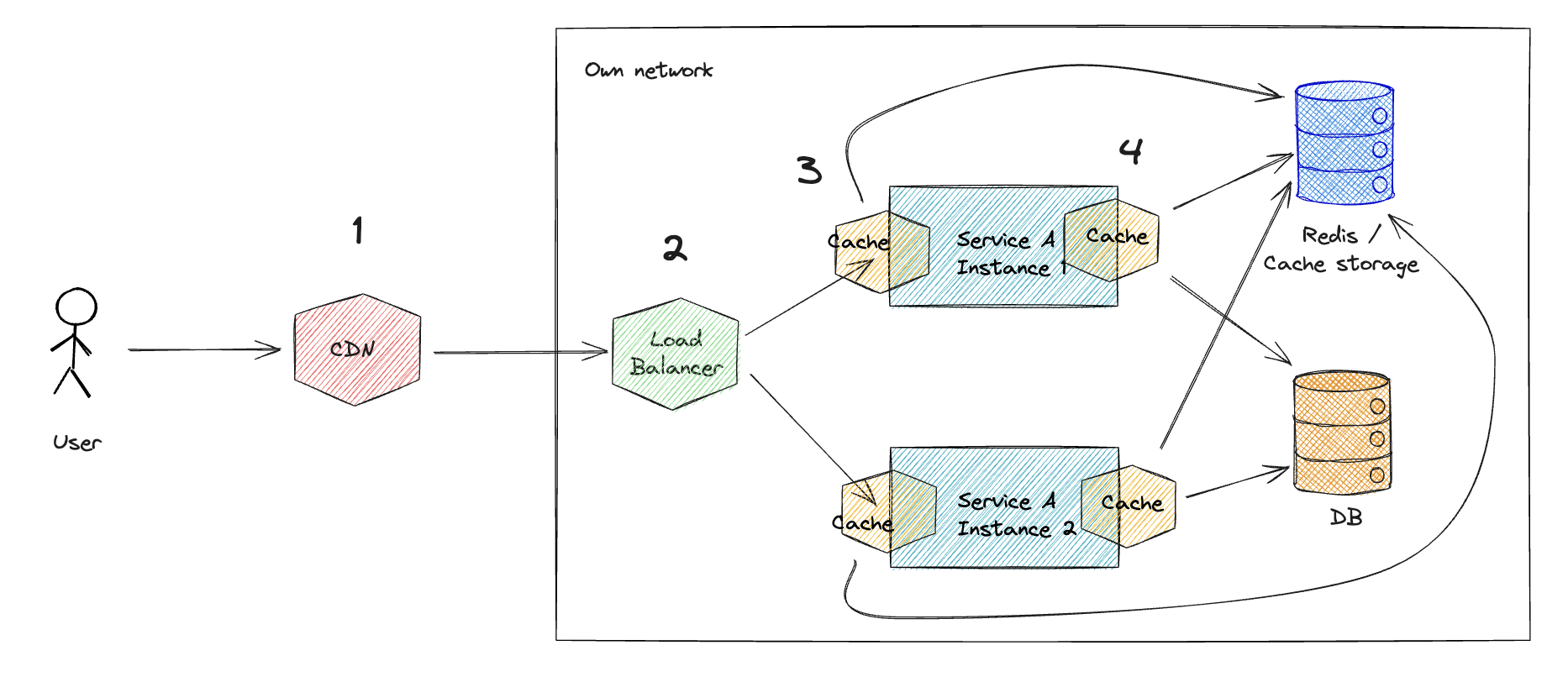
1. Cache In CDN
Content Delivery Networks (CDN) are often geographically located close to the user and can cache the responses. If the CDN is outside your own infrastructure and the response is served from cache, the request will never hit your own infrastructure.

2. Cache In Load Balancer
Load Balancer can cache the responses and serve them to the users. Request will never hit the service, if the response is in the cache.

3. Cache In The Request Handling Middleware
Middleware can cache the responses and serve them to the users. Request will never hit the business logic, if the response is in the cache.
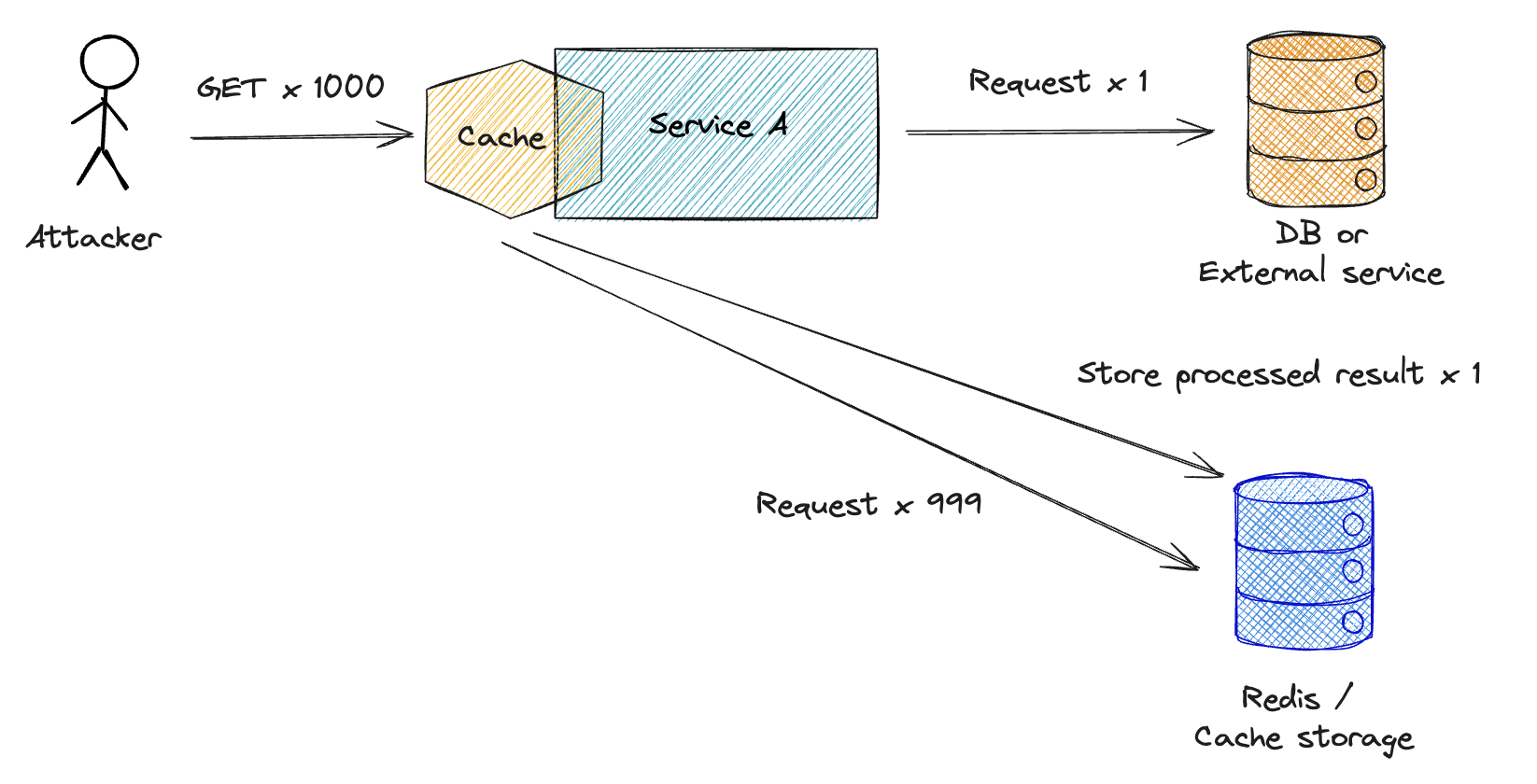
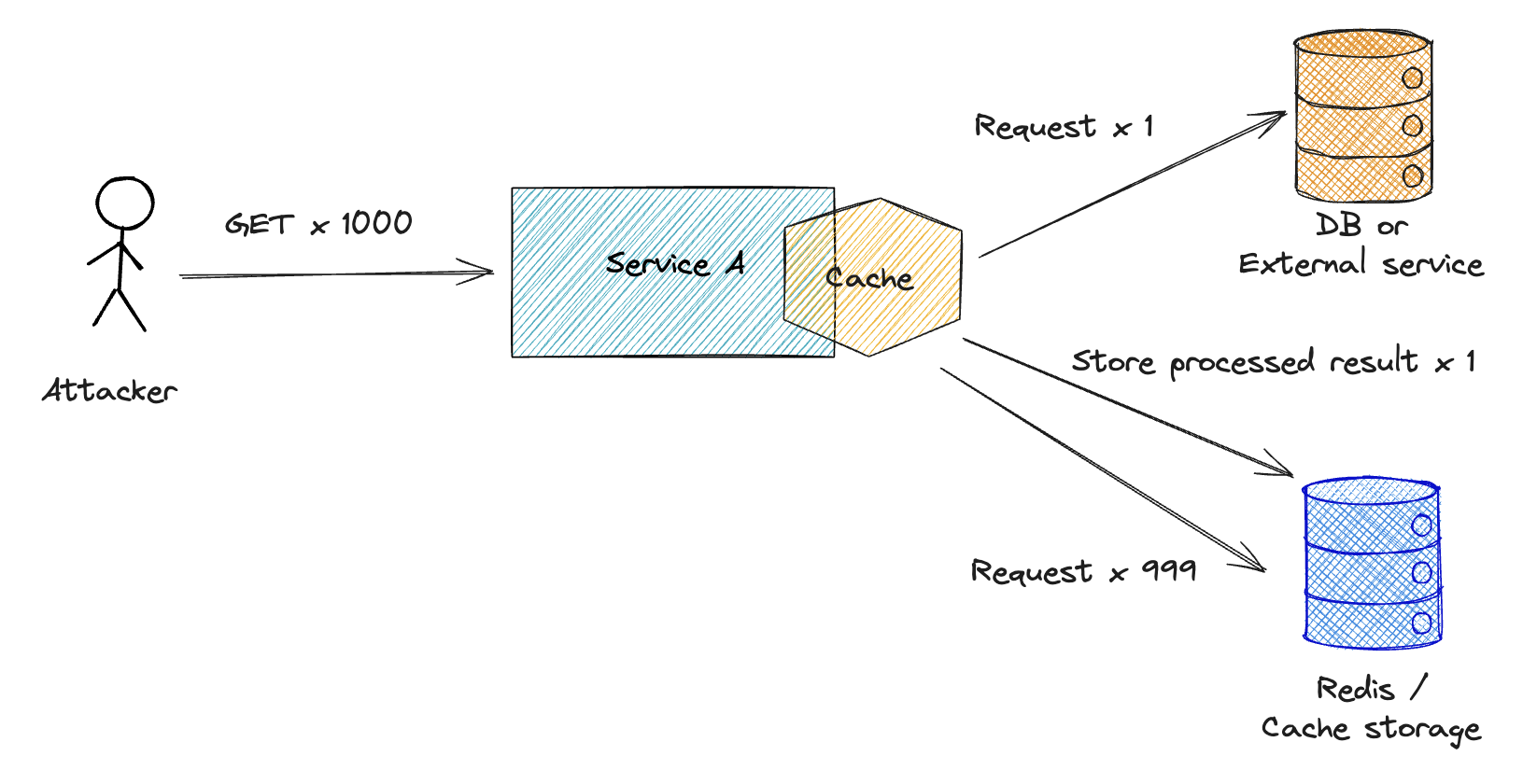
4. Cache In The Application Logic
Application logic can cache data from DB or external services. Request will never hit the DB, external services or slow business logic, if the response is in the cache.
(5. Cache in the Database)
Databases leverage internal caching mechanisms to accelerate response times.
When a database processes a request, it first checks if the requested data is already stored in the shared buffer cache, a memory area that allows for quicker access than disk storage. If the data is in this cache, it can be read directly from memory, resulting in faster response times. If the data is not cached, the database reads it from disk and adds it to the cache for future access.
In addition to data caching, databases also cache query execution plans. Storing these plans in memory can significantly speed up query processing by reusing optimized execution paths for repeated queries.
NOTE: This is especially important to keep in mind when measuring database performance. To obtain accurate performance metrics, always measure after the cache has been warmed up.
Risks with Cached Data
There are only two hard things in Computer Science: cache invalidation and naming things.
– Phil Karlton
When using cached data, there is always a higher risk of serving incorrect data. Risks can be e.g.:
- Stale Data: Cached data may become outdated, leading to users receiving incorrect information. Data my still be the same across the system.
- E.g. The system still shows 10 items available for several minutes even though a customer just bought 5, because the cached data hasn’t been updated.
- Inconsistent Data: Different copies of the data have conflicting values. Changes in the backend might not reflect immediately in the cached data, causing discrepancies.
- E.g. The stock quantity for a product is 10 in one system but 5 in another, meaning some customers see the wrong availability.
- Security Risks: Sensitive data might be cached and wrongly exposed to incorrect or unauthorized users.
Stale Data Mitigation
Serving stale data can be avoided with cache invalidation. Invalidation can be done e.g. by:
- Time-based Expiry: Set expiration times for cached data to ensure it is periodically refreshed.
- Event-based Invalidation: Invalidate the cache when specific events occur, like data updates or user actions.
- Manual Invalidation: Provide mechanisms for administrators to manually clear the cache when needed.
Cache duration should always be set based on the data that is being cached. This is often done with cache headers or in the code-level. Cache duration should be either:
- As long as possible: For e.g. static content and for data that is rarely updated.
- As short as necessary: For dynamic and frequently updated content.
For authenticated requests cache can be shorter than for public requests, but it will still help to reduce the load on the server, especially if users are making the same requests multiple times.
Inconsistent Data Mitigation
Invalidating cache by event is often done in code-level. When functionality changes the data, all caches that are related to that data should be invalidated.
Having a plan how to invalidate the cached data manually is critical. Common case can be e.g. that wrong data is inserted to DB and which is then served to customers. Even when data is fixed from the DB, the cache still serves the wrong data. In these cases there needs to be a way to invalidate the cache.
Security Risks Mitigation
Serving data that belongs to another users happens most likely due to a human error, e.g. by faulty cache configurations, for example by removing user-specific header from used caching key, which would then cache the first users response and serving that to all sequential requests. This kind of incidents happen also to a larger companies. Klarna incident: users saw a subset of their information exposed to other app users.
- Avoid caching user-specific data: Do not cache data that is sensitive or specific to individual users.
- Use short cache duration: Set short cache durations for user-specific data to minimize the risk of serving inconsistent or stale information.
- Use token-based caching: Incorporate user information and expiration details from tokens as part of your caching strategy.
- Avoid caching sensitive data on CDNs: Your own server offers better control over caching based on user information and actions. Storing sensitive data on a CDN can also violate privacy regulations.
Rate Limiting
Rate limiting is an effective way to prevent abuse of APIs and it can help to protect your APIs from denial-of-service attacks.
Rate-limiting can be implemented in various ways:
- IP Address: Limit the number of requests per IP address
- User Account: Restrict requests based on user accounts
- API Key: Enforce limits on API keys
- Specific Endpoints or Methods: Apply different rate limits to specific endpoints or HTTP methods
Rate limiting can be implemented at multiple points in the network stack, including:
- Content Delivery Network (CDN): Rate limiting at the edge network before traffic reaches your infrastructure
- Load Balancer: Apply rate limits at the load balancer level to reduce load on backend servers
- Middleware: Implement rate limiting in the application layer using middleware

Be cautious when applying rate limits based on IP addresses since users behind Network Address Translation (NAT) may share a single public IP address. This can lead to legitimate users being blocked unintentionally.
Blocking a User
Implement mechanisms to block users who violate your API usage policies. This can help protect your APIs from abuse and unauthorized access.
- Block a single authenticated user
- Block user by IP address
- Invalidate authentication tokens
Blocking a single user can be done with a flag in the database, which can be toggled manually or automatically if the user violates the policies.
Blocking a user by IP address can be done in the CDN, WAF, load balancer, or middleware. This is useful if the user is not authenticated but still causing problems.
When applications use JWT tokens for authentication, it is important to have the ability to invalidate tokens when they are no longer needed. This can help when a long-lived token is used to attack the service. The recommendation is to use short-lived access tokens and long-lived refresh tokens. This way, the refresh token can be invalidated if needed and there is no need to check validity of authentication token on every request. The refresh token should also be tied to a specific device so that if the token is stolen, it can’t be used on another device.
Duplicate Request Detection and Prevention
Sites should strive to prevent duplicate (identical) requests. This helps protect your APIs from replay attacks and, for example, prevents users from posting the same comment multiple times.
Often, site users can submit requests or post comments, and some of these duplicate requests may be accidental while others may be malicious. Either way, it’s good practice to prevent these requests as it helps reduce load and maintain data integrity.
Sometimes users need to be authenticated, but there are situations where users must be able to submit data without authentication.

When the user is authenticated, prevention is straightforward since the server can use the user’s session to detect and prevent duplicate requests. For example, a user can only post a comment once per X seconds.
When the user is not authenticated, the server can use other methods to detect and prevent duplicate requests. This detection can be based on the content of the request (e.g., submitter name, email address, or IP address) or a combination of these.
Request
Headers: [x-auth-token] [ip-address]
Body:
{
"reply_to_email": "mail@example.com",
"comment": "This is a great post!"
}
The implementation can be quite simple. For instance, create a key or a hash from selected data and store it in as a cache entry that will invalidate in X seconds. If a new request comes in with the same hash, return an error.
Sometimes it makes sense to return a failure status, but in other cases, it might be better to return a success status while not processing the request. This way, a malicious user doesn’t know if the request was processed or not. For internal applications, it might be preferable to return a failure status so that users can be notified that the request was not processed.
Idempotency
Ensure that your APIs are idempotent, meaning that identical requests can be made multiple times without changing the result beyond the initial application state. This prevents unintended side effects and data corruption.
When the server receives a request (e.g., to create a new order), it should check if the order already exists. If it does, return the existing order. If it doesn’t, create and return a new order. This ensures that subsequent identical requests do not create duplicate orders or modify existing ones unintentionally.

This can be implemented in a same way as duplicate request detection and prevention, but the server should return the same response for the same request. If using a key or a hash is not possible, then the server can check from the DB if the same request has been made before.
This doesn’t only protect the site from external attacks, but also from internal bugs or from network unreability.
Web Application Firewall (WAF)
Web Application Firewall (WAF) should probably be first in the list as it should be the first line of defense for your APIs. The core feature of all WAFs is that they make it easier to block web requests. Lot’s of this functionality could be handled in web server or application code, but WAF provides this functionality out of the box. Likely also more efficiently.
Already out of the box those can provide a good protection against common attacks, including SQL injection, cross-site scripting (XSS), reputational blocking, geoblocking, rate limiting, bot protection and more.
WAF can be implemented in various ways:
- Cloud-based WAF: A cloud-based WAF can protect your APIs from attacks without requiring any additional hardware or software.
- AWS or Azure WAF: Cloud providers can provide WAF services.
- CDN: CDN e.g. CloudFlare can provide WAF services.
- On-premises WAF: An on-premises WAF can provide additional security for your APIs by inspecting traffic before it reaches your servers.
- Load Balancer: Load balancer can provide WAF functionality.
- Application-level WAF: An application-level WAF can provide additional security for your APIs by inspecting traffic at the application layer.
- Middleware: Middleware can provide WAF functionality.
Documented Plan for When the System Is Under Attack
Regardless of the measures taken, it is crucial to have a documented plan in place for when the system is under attack. This plan should include step-by-step instructions detailing actions to take during an attack. The plan should be clear and easy to follow, enabling engineers without much expertise on the topic to take appropriate action effectively.
Database Read Replicas
Read replicas are copies of the main database that handle read queries, improving performance and reducing the load on the primary database.
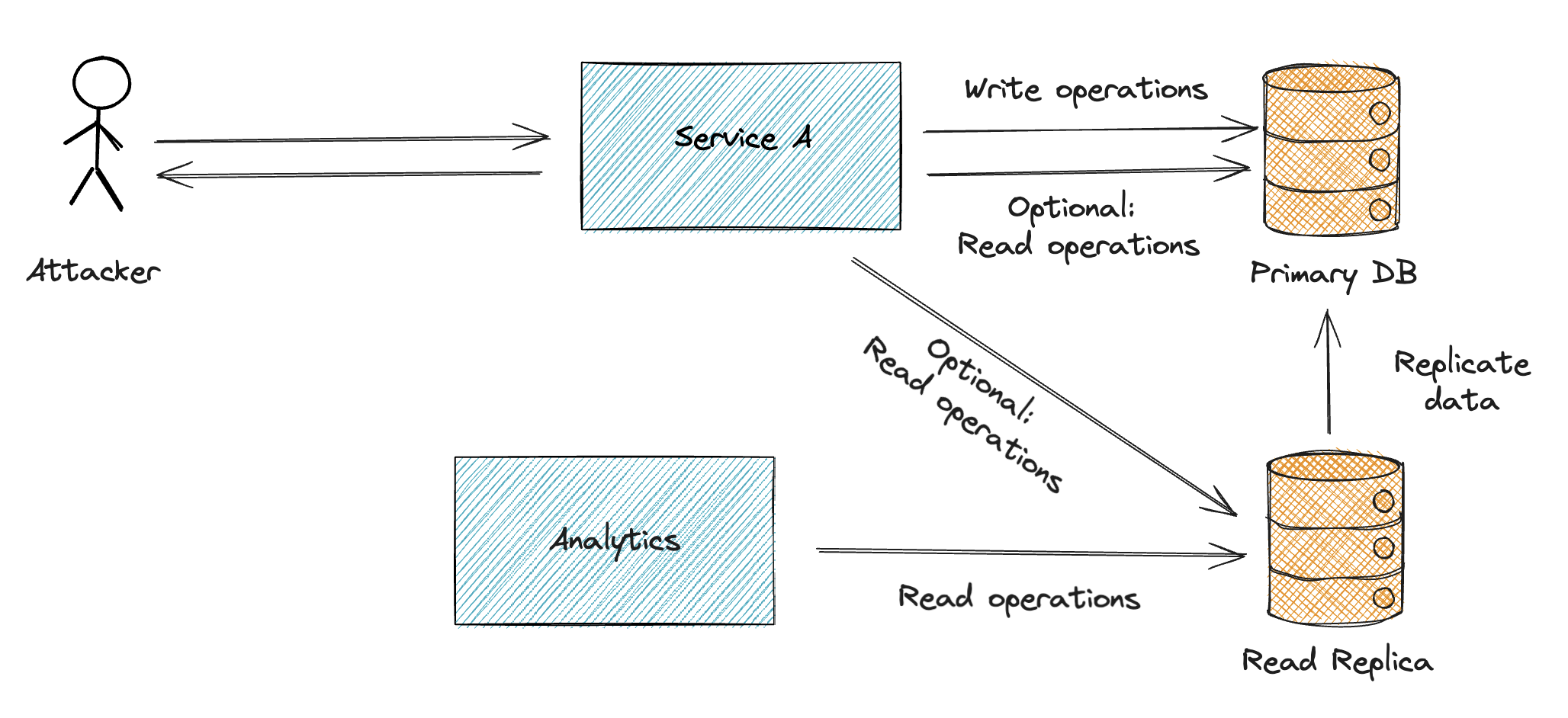
Benefits of Read Replicas:
- Improved Performance: Offload read queries from the main database.
- High Availability: Serve as backups in case the main database fails or during maintenance.
- Reporting and Analytics: Run complex queries without affecting the primary database.
- Audit Logs: Store audit logs separately, preserving main database resources.
High availability and reporting/analytics are common use cases for read replicas. Many services offer the setup of read replicas out of the box, but it can also be implemented manually.
From security point of view, overloading the main database can lead to denial-of-service attacks, and read replicas can help to prevent this.
Bonus: How to Scale an Application to Millions of Users
When you need to be able to serve millions of users, the application should be able to scale horizontally and vertically. Described setup fulfills the requirements for horizontal scaling, but vertical scaling is also needed.
- Horizontal scaling
- Auto-scaling: Automatically add or remove application instances based on demand.
- Vertical scaling
- Increase Resources: Add more CPU, memory, or storage to existing servers.
- Database Optimization: Use read replicas for reporting and analytics to reduce the load on the main database.
Client-Side Security and Helping the Users
There are some steps that do not directly affect the security of the API, but can help the users to use the API in a secure way and improve performance.
CORS
Cross-Origin Resource Sharing (CORS) is a security feature that allows you to restrict which domains can access your APIs.
Access-Control-Allow-Origin: https://my-site.com
CORS protects users by ensuring that a malicious third party cannot create a site like my-fake-site.com and deceive users into using it instead of my-site.com, thus preventing them from stealing user information.
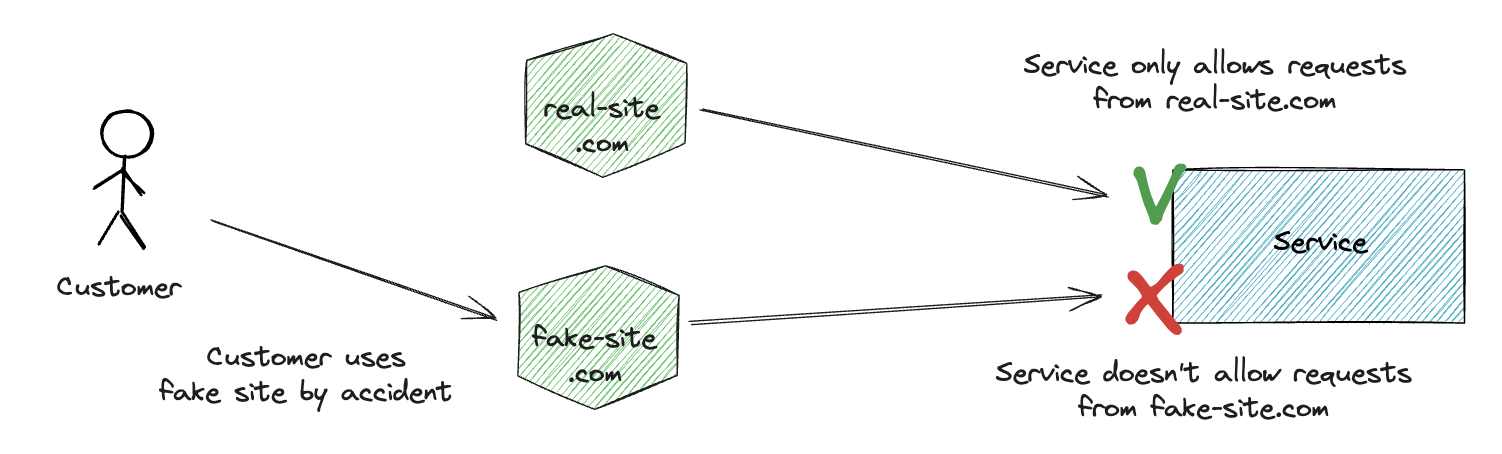
CORS restrictions apply only to web browsers, protecting users from malicious websites. CORS does not apply to server-to-server communications or scripts.
- A malicious site owner can have their own server that calls the API and then sends the data to the malicious site.
- As attackers can still create scripts that directly call the API; therefore, CORS is not a standalone security feature.
CSRF
Cross-Site Request Forgery (CSRF) is an attack that tricks the user into executing unwanted actions on a website where they are authenticated.
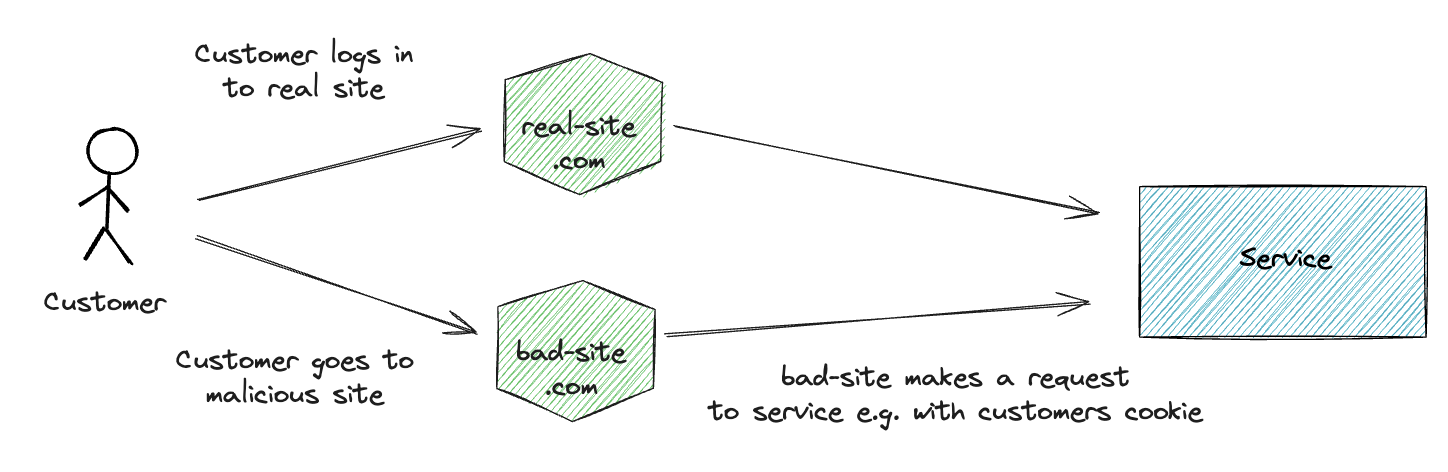
Depending of authentication method, CSRF can be mitigated with e.g.
- SameSite Cookies: Configures cookies to only be sent on requests from the same origin.
- CSRF tokens: A unique token is generated for each user session and included in the request. The server validates the token to ensure the request is legitimate.
- CORS
Browser Caching
Set cache headers correctly to help the users browser to cache the data. This will help the users to get the data faster and reduce the load on the server.
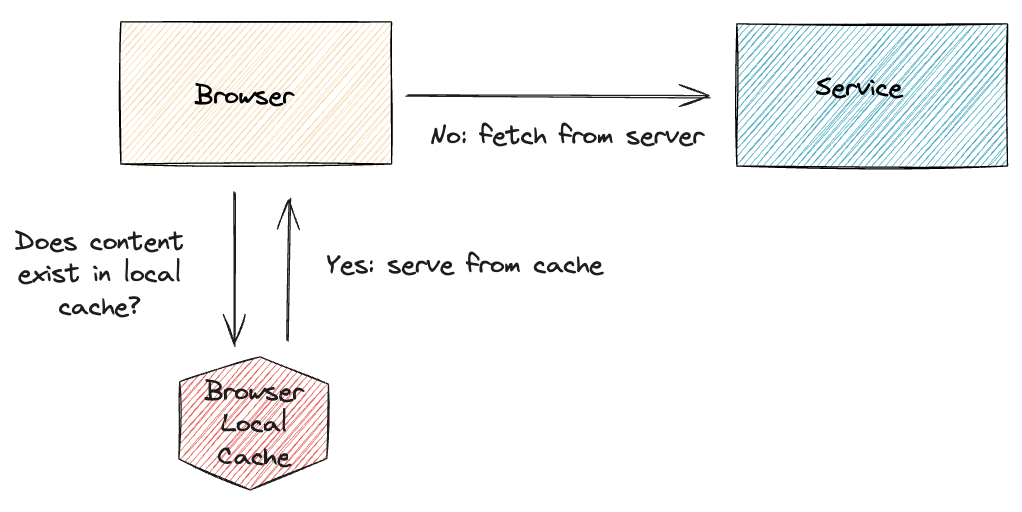
Cache-Control headers can work differently with REST API responses compared to static content, primarily because the nature of the content and the typical usage patterns differ.
CDN may also use these cache headers to decide how it will cache and serve the content to the users without hitting the server.
Cache-Control header directives include:
- no-store: The browser must not store the data in the cache.
- no-cache: The browser stores the data, but it must revalidate the cache with the server before using the cached data. If cached data matches to the server data, the cached data is used.
- public: The data can be cached by any cache, including CDNs.
- private: The data can be cached only by the browser and not by CDNs.
- max-age: The maximum time the data can be cached. During this time content is fresh and after max-age has expired, data is stale.
- must-revalidate: The browser must revalidate the cache with the server before using the cached data.
Directives can be combined:
Cache-Control: max-age=3600, must-revalidate
E.g. this combination ensures that a resource is considered fresh for 3600 seconds. After this period, any subsequent request must revalidate the resource with the origin server before serving it, ensuring the client always gets the most up-to-date version after the max-age period.
Browser Cache Revalidate
If client has ETag or Last-Modified headers, the server can use these to decide if the data has changed and if the client can use the cached data.
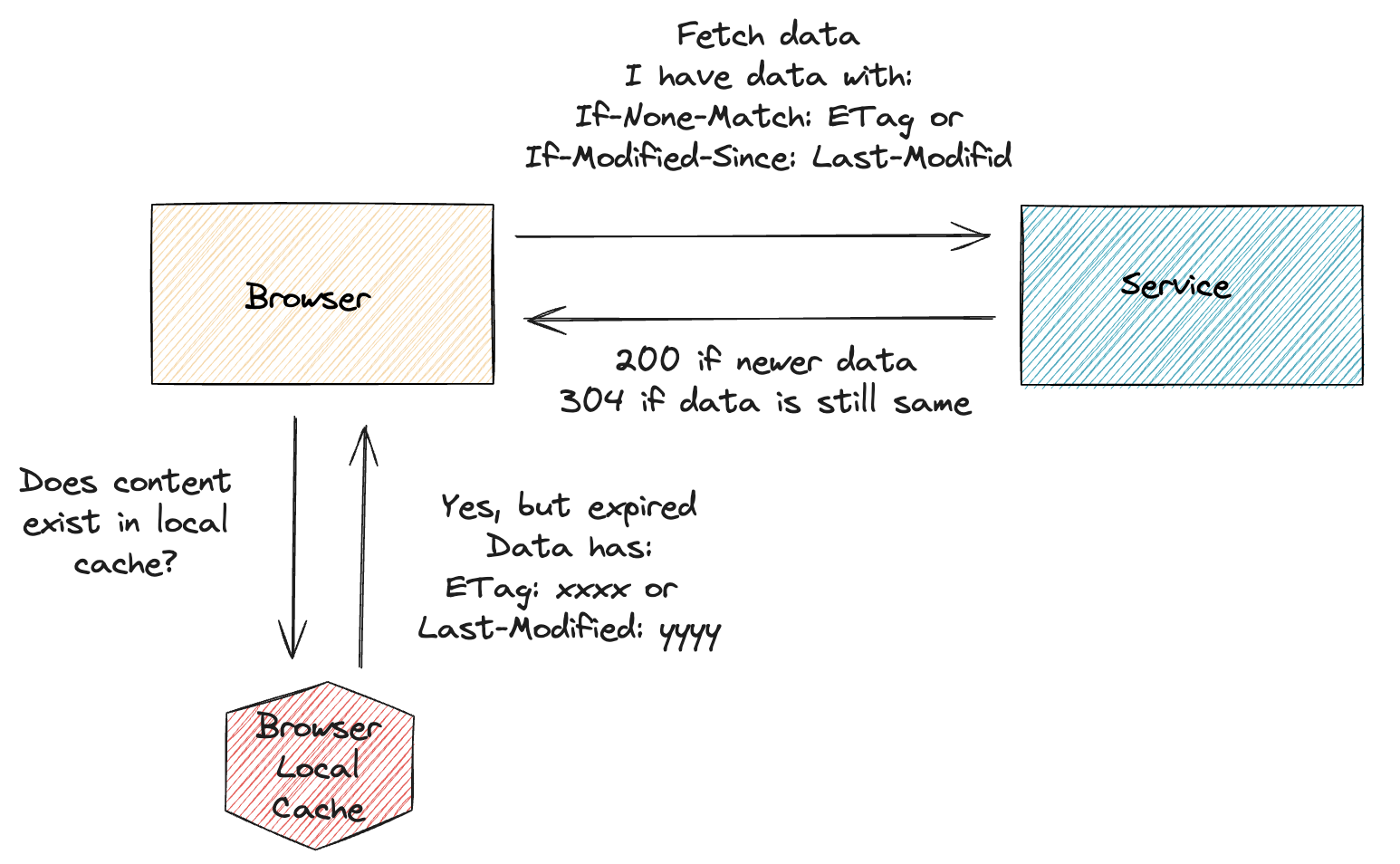
If data is not changed, the server can return 304 Not Modified status code and the client can use the cached data.
Store Different Versions of Data with Vary Header
Vary-header can be used to tell the CDN or browser that the response is different based on the request headers. This can be used to cache the same URL with different headers.
Vary: Accept-Encoding Authorization
E.g. this combination tells the CDN or browser that the response is different based on the Accept-Encoding and Authorization headers.
Security Headers
Prevent account hijacking, clickjacking, and other attacks by implementing security headers in your APIs. These headers can help to protect your APIs from various types of attacks and vulnerabilities. WAF can provide these headers, but they can also be implemented in the application code.
- Content-Security-Policy (CSP)
- For example, a hacker tries to inject a malicious script, that would send data from browser to malicious.site, into your site through a comment section. With CSP, you can restrict the sources from which scripts are allowed to load, blocking this attack.
- Prevents cross-site scripting (XSS) by controlling which resources the browser is allowed to load.
- Strict-Transport-Security (HSTS)
- If a user accidentally types
http://instead ofhttps://when accessing your site, HSTS forces the browser to use HTTPS, ensuring data is encrypted during transmission. - Protects against man-in-the-middle attacks by enforcing secure connections.
- If a user accidentally types
- X-Content-Type-Options
- Prevents the browser from interpreting files as a different MIME type than what is specified, avoiding potential execution of malicious scripts. Mitigates MIME type sniffing attacks.
- Mitigates MIME type sniffing attacks.
- X-Frame-Options
- Prevents your site from being embedded in an iframe on another site, which can protect against clickjacking attacks where users are tricked into clicking on something they didn’t intend to.
- Protects against UI redressing attacks.
- X-XSS-Protection
- Enables the browser’s built-in XSS filtering mechanism. If an XSS attack is detected, the browser will prevent the page from rendering.
- Adds an extra layer of XSS protection, especially for older browsers.
- Referrer-Policy
- Controls the information sent in the HTTP referrer header when navigating from your site to another. For instance, limiting sensitive data exposure by only sending the origin part of the URL.
- Enhances user privacy and reduces the risk of leaking sensitive URLs.
- Permissions-Policys
- Limits the use of certain browser features like camera, microphone, or geolocation. For example, you can restrict access to the geolocation API so only specific pages can request location data.
- Reduces the potential attack surface by restricting access to potentially sensitive APIs.