Managing Issue Alerts
In any system, it’s inevitable that issues will arise at some point. It’s crucial for engineers to have the capability to diagnose and resolve these issues promptly, utilizing effective tooling, such as detailed logs, comprehensive error tracking, and thorough monitoring solutions.
Equally important is the ability for engineers to be notified immediately upon the occurrence of an issue. Prompt notifications enable the swift addressing of problems, minimizing potential impacts. These notifications can be facilitated through alerts generated by logs, error tracking systems, and monitoring tools.
The delivery of these notifications can be via email, chat, or other communication platforms. It’s vital that these alerts reach the relevant individuals promptly and without delays.
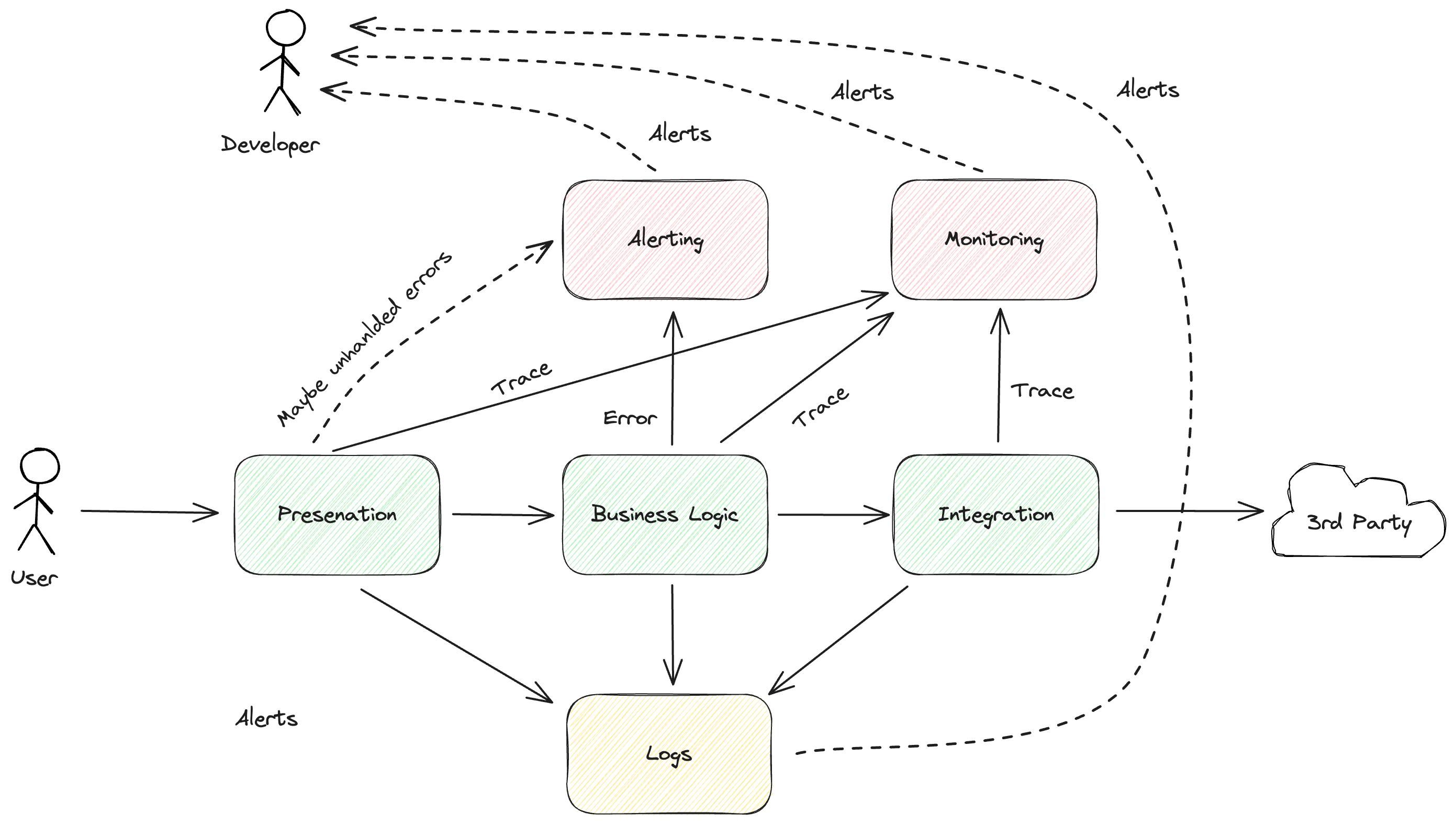
Upon receiving notifications, the engineering team must manage and respond to these alerts efficiently. This post aims to provide a concise guide on how to effectively manage issue alerts.
Managing Issue Alerts
Ideally, each alert should signal a situation requiring attention. If an alert is triggered for an issue that doesn’t necessitate engineering intervention, then it arguably shouldn’t be an alert in the first place. This ensures that the team can trust that every alert is significant and requires action.
There are instances where an issue might not require immediate attention. For example, alerts based on monitoring might resolve independently, such as when an API request fails due to a temporary network error. However, in situations where these kinds of alerts are not possible from monitoring, but stem from logging or error tracking, teams must efficiently manage them, resolve them swiftly and communicate clearly. This way it is clear if the issue is handled or not.
Examples:
- API request fails because of network error
- This issue might not require immediate action. It’s typically a monitoring alert that resolves on its own when the called API is responding again.
- API response error due to incorrect data
- This requires intervention and should trigger an error tracking alert.
- This should be triggered from the business logic, as from there we can determine if the issue is critical or not.
Alert Fatigue
One of the most significant challenges in managing alerts is alert fatigue. When engineers receive too many alerts, especially those that don’t require action or are false positives, they begin to ignore or dismiss all alerts, including critical ones. This undermines the entire alert system and can lead to serious issues going unnoticed.
Signs of alert fatigue:
- Alerts are routinely ignored or dismissed without investigation
- Engineers complain about notification overload
- Critical issues are missed because they’re buried in noise
- Team stops trusting the alert system
Preventing alert fatigue:
- Regular Alert Review: Periodically review all alerts to ensure they still provide value. Remove or adjust alerts that consistently don’t require action.
- Proper Thresholds: Set alert thresholds carefully. An alert that triggers daily for non-issues should be tuned or removed.
- Actionable Alerts: Every alert should have a clear action associated with it. If you can’t define what action to take, reconsider if it should be an alert.
Maintaining a healthy alert system requires ongoing effort. Teams should regularly review alert patterns and be willing to delete or modify alerts that aren’t serving their intended purpose.
Process overview
To ensure efficient issue resolution, teams need a clear process for handling incoming alerts. The following workflow helps maintain clarity on which issues are being addressed and by whom:
- New issue alert arrives
- Comment: The initial responder should outline the action plan
- Immediate Fix: Address the issue at once.
- Fix Later: Schedule a task in the task management system.
- Silence alert: To prevent notification overload, archive/ignore the issue
- If possible, set a reminder or duration for ignore to avoid overlooking it.
- Tracking:
- Indicate whether someone is addressing the issue or if it’s already resolved, using tools like emoji reactions in Slack for clarity (e.g. :check_mark:, :construction:)
- If the system allows, document the issue’s resolution process, including linking to relevant tasks or explaining why it was archived, as seen in platforms like Sentry.
- Comment: The initial responder should outline the action plan
Benefits of Defined Process
Defined process might seem restrictive for the team, but it can actually increase autonomy.
- Autonomy: Trust in the team’s ability to manage issues independently enhances workplace autonomy, eliminating the need for constant oversight.
- Peace of Mind: Effective issue management assures all team members that problems are being addressed competently, providing mental comfort.
- Operational Efficiency: A well-orchestrated alert system contributes to the smooth operation of the system, ensuring that issues are resolved promptly and efficiently.