SLI, SLO, and SLA - A Brief Guide
Service Level Agreements (SLA), Service Level Objectives (SLO), and Service Level Indicators (SLI) are key concepts for measuring and managing service reliability.
In short:
- SLI is what we measure.
- SLO is what we aim for.
- SLA is what we promise.
Service Level Indicator (SLI)
SLIs are the actual measurements of your service’s behavior. What are you measuring?
Definition: A quantifiable metric that measures a specific aspect of service performance.
Relationship with Metrics: SLIs are specific metrics chosen to represent service quality from the user’s perspective. Your system collects hundreds of metrics (CPU, memory, request counts, etc.), but SLIs are the subset that actually matter for reliability and user experience.
All SLIs are metrics, but not all metrics are SLIs.
Common SLIs:
- Availability: Percentage of successful requests
- Example:
(successful_requests / total_requests) * 100
- Example:
- Latency: Response time percentiles
- Example: 95% of requests complete in < 200ms
- Error rate: Percentage of failed requests
- Example:
(failed_requests / total_requests) * 100
- Example:
- Throughput: Requests processed per second
- Example: 1,000 req/s
Service Level Objective (SLO)
SLOs are your internal targets for service reliability. What are you aiming for?
Definition: A target value or range for an SLI over a specific time window.
Example SLOs:
- Availability SLO: 99.9% uptime per month
- Service must be reachable and responding
- Allows ~43 minutes of downtime per month (complete outages, timeouts)
- Latency SLO: 95% of requests < 200ms
- p95 latency stays under threshold
- Error rate SLO: < 0.1% failed requests (when service is available)
- Maximum 1 error per 1,000 requests due to server errors (5xx)
Service Level Agreement (SLA)
SLAs are your promises to customers, with consequences when you fail.
Definition: A formal commitment to customers about service reliability, including consequences for not meeting targets.
Key components:
- Target metric: What is measured (availability, latency, etc.)
- Threshold: The promised level (e.g., 99.95% uptime)
- Time window: Measurement period (monthly, quarterly)
- Consequences: Penalties for breaching (refunds, credits, etc.)
Relationship Between SLI, SLO, and SLA
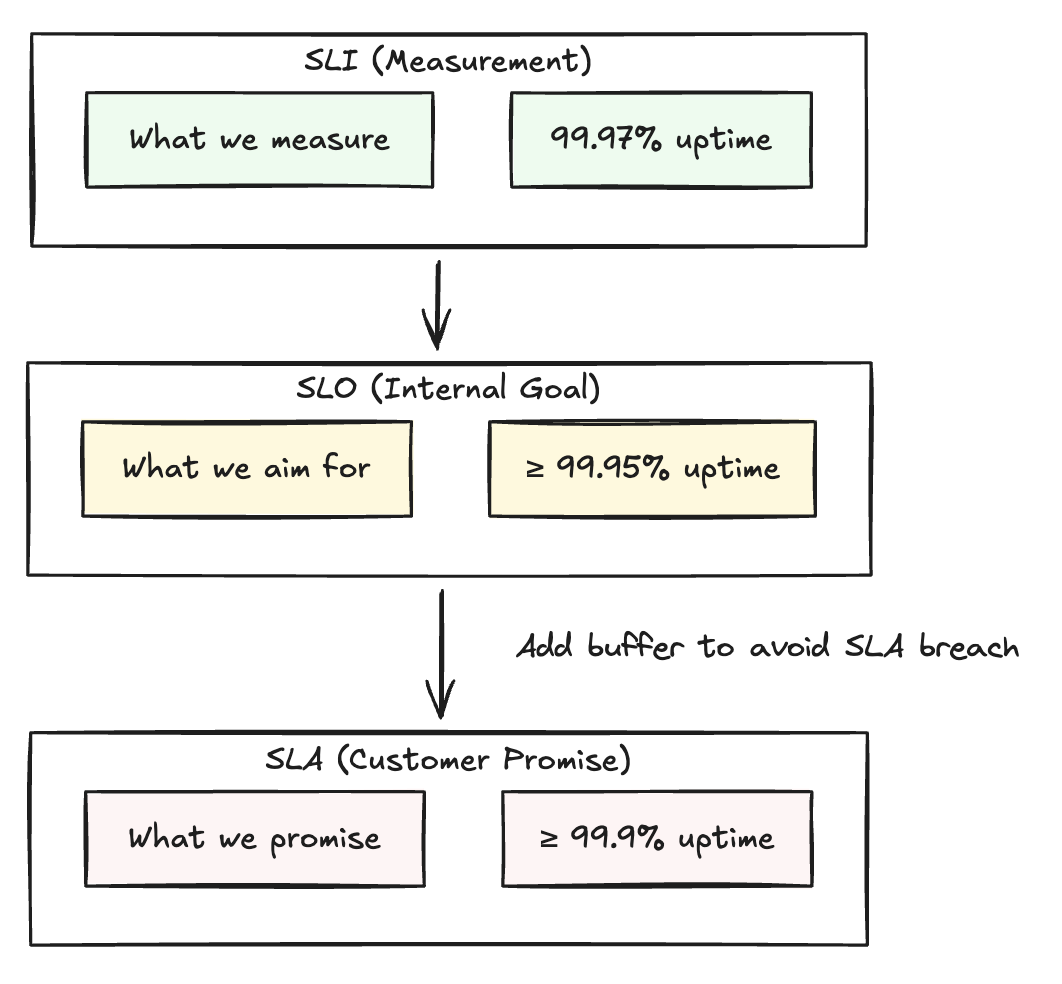
Important: SLOs should be stricter than SLAs to provide a safety buffer and trigger internal actions before customer impact occurs.
SLOs (Internal targets)
- Availability SLO: 99.95% uptime per month
- Service reachable and responding
- Error budget: 21.6 minutes of downtime/month
- Latency SLO: p95 < 200ms, p99 < 500ms
- Error rate SLO: < 0.1% (1 in 1,000 requests when service is available)
SLA (Customer promise)
- Availability: 99.9% uptime per month
- Consequence: 10% monthly credit if breached
- Consequence: 25% credit if < 99.5%
- Latency: p95 < 300ms
- Consequence: 5% credit if breached consistently
- Measurement: Based on successful API health checks every 60 seconds
Error Budget
Error budget is the allowed amount of unreliability, derived from your SLO:
- SLO: 99.95% availability
- Error budget: 0.05% (100% - 99.95%)
- Monthly requests: 10M
- Allowed failures: 5,000 requests or 21.6 minutes downtime
Error budget benefits:
- Balance reliability vs. features: Spend the budget on innovation when reliability is good
- Objective decision-making: Stop deployments when the budget is exhausted
- Shared responsibility: Creates alignment between dev and ops teams
- Prevent over-engineering: Knowing when “good enough” is actually good enough
Example scenario:
Month: January
Total requests: 10,000,000
Failed requests: 3,000
Current availability: 99.97%
Error budget used: 60% (3,000 / 5,000)
Status: ✅ Healthy - can continue rapid deployments
If the error budget reaches 90%, trigger these actions:
- Slow down feature deployments
- Focus on stability improvements
- Increase testing and review rigor
- Investigate reliability issues
Conclusion
SLIs, SLOs, and SLAs form a clear chain: measure what matters and set internal targets stricter than customer promises.
Start with a few key SLIs, derive SLOs from business needs, and only commit SLAs when you can reliably meet them.